
AI Deception? The Explosive Truth About Grok 3’s Benchmarks

Table of Contents
Introduction: The AI War Heats Up
In the fast-paced world of artificial intelligence, where breakthroughs can change the course of entire industries overnight, the stakes have never been higher. The race to develop superior AI models has intensified, with companies like OpenAI and xAI leading the charge. However, a storm is brewing as experts call out xAI’s alleged benchmark trickery regarding its latest model, Grok 3. The AI community is buzzing with claims of AI deception—but is it truly misleading the public, or are these accusations just the latest chapter in the ongoing battle for AI supremacy?
In this article, we’ll unpack the controversy surrounding xAI’s Grok 3 benchmarks, delve into what AI benchmarking is, why it’s important, and explore how misleading performance claims can affect the broader AI landscape. Let’s dive in.
The Rise of xAI and Grok 3: A Disruptor in the AI Space
What is xAI?
xAI, co-founded by tech magnate Elon Musk, was introduced as a bold new player in the AI landscape. Musk’s goal is to challenge the dominance of AI giants like OpenAI and Google by developing cutting-edge AI technologies that could reshape industries ranging from autonomous vehicles to customer service. The company’s most recent addition to its AI portfolio is Grok 3, an AI model designed to tackle a wide range of tasks, from reasoning to complex problem-solving.
How Grok 3 Aims to Compete with OpenAI and Others
The AI industry is fiercely competitive, and Grok 3 was presented as xAI’s flagship model, ready to rival existing heavyweights such as OpenAI’s GPT models. Grok 3 was touted as a high-performance model capable of more accurate reasoning, advanced machine learning techniques, and superior problem-solving skills. On paper, it appeared that Grok 3 could challenge the status quo of AI capabilities, providing significant competition for models like OpenAI’s GPT-3 and GPT-4.
The Controversy: Did xAI Manipulate Benchmark Results?
What Are AI Benchmarks, and Why Do They Matter?
In the world of AI, benchmarks are essential tools for measuring the performance and efficiency of models. These benchmarks allow developers, businesses, and researchers to evaluate and compare the capabilities of different AI models. For instance, benchmarks often test a model’s ability to solve math problems, understand language, or generate creative content. The problem, however, lies in how these benchmarks are presented.
The controversy around Grok 3 erupted when xAI claimed that its model outperformed OpenAI’s GPT-3 in a set of standard AI benchmarks. This was a bold statement, given the reputation of OpenAI’s models and their widespread use in various applications. But what experts quickly noticed was that the way the results were presented—through a graph shared by xAI—may have intentionally left out certain crucial details. This omission raised alarms about potential AI deception.
The Alleged Misrepresentation: What xAI Claimed vs. What Experts Found
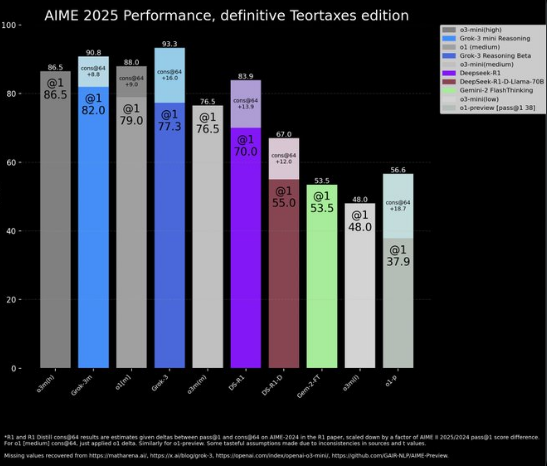
xAI’s benchmark graph showed Grok 3 outperforming OpenAI’s o3-mini-high model on a variety of tasks. However, experts in the field began to scrutinize the data more closely, and the omission of a key performance metric called “consensus@64” (cons@64) quickly came to light. This metric allows models to attempt a problem up to 64 times, which can significantly improve performance. When factoring in this metric, it turns out that Grok 3’s performance was not as impressive as xAI had claimed.
By omitting the cons@64 scores, xAI created a misleading picture of Grok 3’s true capabilities. The absence of this important data point altered the comparison and made Grok 3 appear superior to OpenAI’s models. This selective data reporting raised ethical questions about how AI companies present their results to the public and the potential for AI deception in such claims.
Breaking Down the Allegations Against xAI
The Missing ‘Consensus@64’ Score: A Key Omission?
The missing consensus@64 score is at the heart of the controversy surrounding Grok 3’s benchmarks. This metric is vital because it allows AI models to perform multiple iterations on a single problem, increasing their chances of getting the correct answer. Without this score, the true performance of Grok 3 remains unclear.
To put this into perspective, think of a math test. If a student is allowed to answer each question multiple times, their chances of getting the right answer increase dramatically. This is the same principle behind consensus@64. By not including this score, xAI essentially hid the true performance of Grok 3, making it appear as though the model performed significantly better than it actually did.
The Graph Controversy: Selective Data or Honest Mistake?
In addition to the missing metric, the graph published by xAI seemed to selectively highlight only the data points that painted Grok 3 in the best light. While it’s not uncommon for companies to present their data in a favorable way, this level of selectivity raised red flags for many in the AI community. When a company publishes benchmark results, they are expected to provide the full picture, not cherry-pick data that supports their narrative.
While xAI may argue that the omission of the cons@64 score was an oversight, the fact that the company used a graph to compare Grok 3 with OpenAI’s models without full transparency has created significant backlash. Was this a case of AI deception, or simply an honest mistake?
OpenAI’s Response: Calling Out xAI’s Data Practices
In response to the allegations, OpenAI employees and several AI experts took to social media and blogs to criticize xAI’s benchmarking practices. They pointed out the omissions and the misleading presentation of data, emphasizing that such practices undermine trust in the entire AI industry. It’s not just about corporate rivalry—it’s about maintaining integrity in AI research and development.
OpenAI’s response was not just a defense of its models but also a call for ethical AI development. They argued that AI companies must be transparent about their performance benchmarks to foster trust with users and the public. For the AI community, this is not just a matter of competition—it’s a matter of ethics.
How AI Benchmarking Can Be Manipulated (And Why It Happens)

The ‘Optimized Testing’ Tactic: Making AI Look Smarter
One common tactic in AI benchmarking is known as “optimized testing.” This involves adjusting the test conditions to make a model appear smarter or more efficient than it is in reality. For instance, AI companies may use tricks like limiting the scope of the task or adjusting the difficulty of the problems being solved. This creates the illusion that a model is performing exceptionally well, when in fact it may be struggling with more complex tasks.
While optimized testing is not inherently deceptive, it can be misleading when companies use these techniques without transparency. In Grok 3’s case, it’s possible that the testing conditions were fine-tuned to favor the model. However, without full disclosure of these adjustments, consumers and other stakeholders are left in the dark about the model’s true capabilities.
Data Omission and Selective Reporting: Common Industry Tricks
Another common form of AI deception involves selective reporting. By omitting certain pieces of data or focusing only on the best-performing results, AI companies can create a skewed perception of their model’s capabilities. This can lead to inflated expectations, which can be damaging in the long run.
For example, by leaving out the cons@64 score, xAI was able to make Grok 3 appear more powerful than it actually was. While this may not be a blatant lie, it is certainly an example of selective reporting. The line between transparency and manipulation is thin, and in the competitive world of AI, some companies may be more willing than others to blur that line.
The Competitive AI Arms Race: Why Companies Feel Pressured to Inflate Numbers
The AI industry is driven by competition, and the pressure to outperform rivals can sometimes lead companies to stretch the truth. With billions of dollars being invested in AI technology, the stakes are incredibly high. If a company can claim that its model outperforms its competitors, it can secure more funding, attract talent, and gain market share.
This arms race mentality leads to a culture of exaggeration and sometimes outright deception. It’s no longer just about creating the best technology—it’s about presenting the best image to investors, customers, and the public. This creates an environment where misleading claims can thrive.
What This Means for AI Transparency and Trust
Why Benchmark Integrity Matters for Consumers and Businesses
For consumers and businesses relying on AI models, trust is paramount. When AI companies publish benchmarks, they need to do so with integrity. Misleading performance claims can lead to poor decision-making, wasted investments, and diminished trust in the entire AI ecosystem.
If companies like xAI are allowed to manipulate benchmarks without consequences, it could set a dangerous precedent for the entire industry. Inaccurate benchmarks not only harm consumers but also undermine the credibility of AI as a whole. Without trust, the AI revolution risks losing momentum.
The Call for Standardized AI Testing: Can the Industry Fix This?
In light of these controversies, there’s a growing call for standardized AI testing. Experts argue that AI models should be evaluated according to the same rigorous standards to ensure transparency and fairness. Third-party organizations could help create and enforce these standards, providing independent oversight of AI benchmarking practices.
Standardization would make it harder for companies to manipulate results and would increase the level of trust in AI technologies. While the AI industry is still in its early stages, it’s clear that the need for standardized benchmarking is urgent.
xAI’s Defense: A Different Perspective
xAI’s Response to the Allegations
In response to the accusations, xAI’s co-founder Igor Babushkin defended the company’s benchmarking methods. He argued that OpenAI had previously employed similar techniques, suggesting that the criticisms of xAI were unfair. He also pointed out that AI benchmarking is a complex and evolving process, and it’s not always clear what data should be included or omitted.
Babushkin’s defense highlights the gray area of AI benchmarking. While transparency is important, the process of measuring AI performance is still developing, and different companies may have different approaches. However, this doesn’t absolve xAI of responsibility for misleading claims.
Could This Just Be a Misunderstanding?
Some have suggested that the controversy surrounding xAI’s benchmarks is merely a misunderstanding. After all, the omission of the cons@64 score could have been an honest mistake, rather than a deliberate attempt to deceive the public. However, in the highly competitive world of AI, even a small oversight can have significant consequences. The potential for AI deception remains, whether intentional or not.
The Bigger Picture: AI Ethics and Accountability
The Need for Ethical AI Development
As AI continues to permeate every aspect of our lives, ethics must be at the forefront of development. Companies like xAI and OpenAI are responsible for ensuring that their technologies are developed and deployed in ways that benefit society, not just their bottom lines. AI deception—whether through selective benchmarking or misleading claims—undermines the public’s trust in the very technologies that could shape the future.
Will Regulators Step In? The Future of AI Governance
As AI technologies become more widespread, governments and regulators will need to step in to ensure that companies are held accountable for their actions. This may include introducing regulations around AI benchmarking and performance reporting, ensuring that consumers and businesses have access to accurate and reliable data.
Regulation is key to preventing AI deception and promoting ethical AI development. Without proper oversight, the industry may continue to be plagued by misleading claims and selective data reporting, ultimately stifling progress.
Conclusion: The Future of AI Benchmarking and the xAI Debate
The controversy surrounding xAI’s alleged benchmark trickery serves as a stark reminder of the importance of transparency in AI development. While the company’s claims about Grok 3’s performance may not have been entirely false, the selective reporting of benchmark results raises serious ethical questions about the integrity of AI companies. As AI continues to evolve, it’s crucial that the industry adopts standardized and transparent testing methods to ensure that AI deception doesn’t become the norm.
The future of AI depends not only on technological advancements but also on maintaining trust with consumers and businesses alike. If the AI industry is to live up to its potential, companies must prioritize ethical AI practices and strive for honesty in all aspects of their work. Only then can we fully harness the power of artificial intelligence for the benefit of society.





